In supervised learning, we simply have a batch data in the form of training example, and fit a statistical model that maps features to target variables by minimizing a loss function. This loss function, for example, could represent the negative log-likelihood of a probabilistic model. Reinforcement learning is different because which statistical model parameters are chosen determine which data is observed next, and we’d like an optimal one starting from each different point. Intuitively, it sounds like this later setting would be more computationally intensive in terms of data required, and indeed this is the case.
In particular, a key characteristic which distinguishes optimization methods for supervised learning and reinforcement learning is the double sampling problem. Each step of a supervised learning procedure requires one data point, whereas each step of a reinforcement learning method requires two. In this blog post, we’ll rigorously explain why this is the case. Before doing so, let’s first explain why in supervised learning we only need one training example per step.
In supervised learning, we try to minimize an objective which may be written as an expected value over a collection of random functions, each of which is parameterized by realizations of a random variable. Specifically, we care about the following stochastic program:
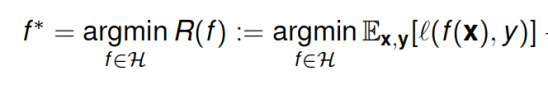
Here f is a statistical model that takes in feature vectors x and maps them to target variables y, 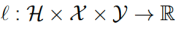 is a loss function that penalizes the difference between
is a loss function that penalizes the difference between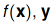 and quantifies the merit of a statistical model f evaluated at a particular sample point x.
and quantifies the merit of a statistical model f evaluated at a particular sample point x.
To solve the above minimization when no closed form solution is available since the expectation cannot be evaluated (due to its dependence on infinitely many training examples), we require stochastic approximation. Thus, we perform gradient descent on the objective, but then approximate the gradient direction with an instantaneous unbiased estimate called the stochastic gradient. This is how maximum likelihood estimation, support vector machines, and many other searches for regression coefficients, are solved. It is not overstating things to say that the backbone of most modern supervised learning systems is a numerical stochastic optimization procedure called stochastic gradient method, which at each time implements the following
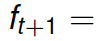
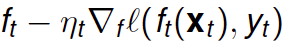
The validity of this approach crucially depends on unbiased estimates of the gradient being attainable via the stochastic gradient which requires only one training example to evaluate, i.e., there is only one sample 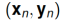 required to evaluate the stochastic gradient involving our current statistical model.
required to evaluate the stochastic gradient involving our current statistical model.
The landscape is different in reinforcement learning. We are faced with a more intricate question: not just how can we find a statistical model that maps features to targets, but how can we find a whole collection of models that map features to targets, such that when we condition on starting from an initial observation, we map to a initialization-specific target variable. Recall the basic setup of reinforcement learning from my previous post:
 The goal in this setting is to formulate the average discounted accumulation of rewards when starting in a given state, which is called its value:
The goal in this setting is to formulate the average discounted accumulation of rewards when starting in a given state, which is called its value: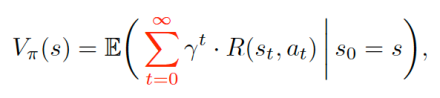 and to choose the action sequence to maximize value. Since searching over infinite sequences is generally intractable, we typically parameterize the action sequence as a time-invariant (stationary) mapping called a policy:
and to choose the action sequence to maximize value. Since searching over infinite sequences is generally intractable, we typically parameterize the action sequence as a time-invariant (stationary) mapping called a policy: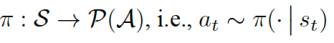
For further reference, when we condition the value function on a particular policy and initially chosen action, we call that the action-value (or Q) function, defined as:
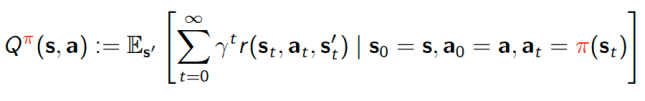 There are two dominant approaches to finding an “optimal” policy, i.e. the one that makes the value as large as possible. One simply tries to do gradient ascent on the value function with respect to the policy, which is colloquially called “direct policy search.” The other, called approximate dynamic programming, employs ideas pioneered by Richard Bellman in the 50s. We’ll explain what each of these does, and why both approaches require at least two data points per update.
There are two dominant approaches to finding an “optimal” policy, i.e. the one that makes the value as large as possible. One simply tries to do gradient ascent on the value function with respect to the policy, which is colloquially called “direct policy search.” The other, called approximate dynamic programming, employs ideas pioneered by Richard Bellman in the 50s. We’ll explain what each of these does, and why both approaches require at least two data points per update.
First, let’s focus on approximate dynamic programming, where we unravel the (action-)value function into its first term, the reward observed at the outset of the trajectory, and all subsequent rewards, which through some clever application of the properties of a Markov Process (such as the Kolmogorov-Chapman equation), yields the Bellman optimality equation. This expression, for a general continuous state and action space, is a fixed point equation that one must satisfy for each initial point in the space, i.e., we would like to find Q functions that satisfy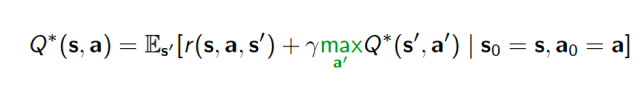 for all s and a. The above expression is called the Bellman optimality equation (Bellman ’57). Now, we can define the temporal difference (Sutton ’98) as:
for all s and a. The above expression is called the Bellman optimality equation (Bellman ’57). Now, we can define the temporal difference (Sutton ’98) as: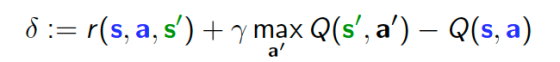
which is how far the Q function is from satisfying the Bellman optimality equation for a given state-action-state pair. We can define the average deviation from optimality when starting from a given s and a as:
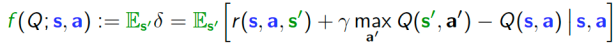
If we define an ergodic distribution over the state and action spaces, that is, a distribution for which visiting any state-action pair occurs with positive probability, we can transform the above stochastic fixed point problem into an optimization problem where the decision variable is the Q function. Moreover, the universal quantifier regarding initialization may be re-expressed as an additional expectation over all starting points of the Markov Decision Process trajectory. Therefore searching for the optimal (action-)value function involves an optimization problem involving nested dependent expectations.
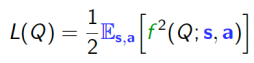
This observation was famously explained by Sutton in 2009 (“A Convergent O ( n ) Algorithm for Off-policy Temporal-difference Learning with Linear Function Approximation”).
The presence of the inner and outer expectation mean that computing the functional stochastic gradient of the above loss will depend on an additional inner expectation that must itself be estimated by a second process. Therein lies the origins of the double sampling problem in approximate dynamic programming (ADP). The fact that the nested expectations must be overcome while ensuring the Q function parameterization remains stable and also moderate memory is a key challenge of ADP. The most convincing ways of dealing with this in ADP is to either connect ADP with stochastic compositional optimization and formulate a time-average recursive estimator or a sample average approximation of some the inner expectation to plug into the outer one, as in some of my recent works (“Policy Evaluation in Continuous MDPs with Efficient Kernelized Gradient Temporal Difference” and “Nonparametric stochastic compositional gradient descent for q-learning in continuous Markov decision problems”) or a clever use of the Fenchel dual to reformulate the Bellman optimality equation as a saddle problem (“Stochastic Dual Dynamic Programming (SDDP) ” and “SBEED: Convergent Reinforcement Learning with Nonlinear Function Approximation”).
The other dominant approach to reinforcement learning, as previously mentioned, is direct policy search, of which the canonical method is policy gradient ascent (“Policy Gradient Methods for Reinforcement Learning with Function Approximation”). It sounds intricate, but really, it’s gradient ascent on the value function defined above, while using the log trick and some other properties of the Markov process. In particular, if we parameterize the policy: 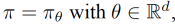 and define the value function above as J. Then the Policy Gradient Theorem states that:
and define the value function above as J. Then the Policy Gradient Theorem states that: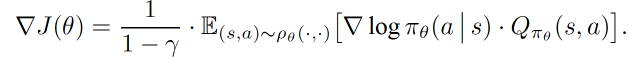
where the expectation is taken over 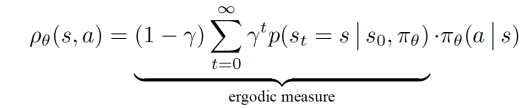
that is parameterized by the policy parameters. Policy gradient ascent simply executes the update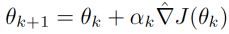 but the validity of this update crucially requires the gradient estimate here to be an unbiased estimate of the aforementioned expanded expression.
but the validity of this update crucially requires the gradient estimate here to be an unbiased estimate of the aforementioned expanded expression.

In particular, the Q function in the policy gradient is itself another expectation (see the definition of Q from the ADP discussion) but taken over a distribution that depends on the policy parameters. Hence, from a completely different perspective than Bellman’s dynamic programming equations, we have arrived at the fact that direct policy search runs into double sampling.
Many policy search methods attempt to overcome this setting by operating in a hybrid scenario where the Q function may be estimated in a batch fashion called episodic reinforcement learning, or simply plug in a mini-batch estimate for Q into the infinite horizon case and hope for the best. But in general, unbiasedly estimating the Q function in the infinite horizon case remains a challenging problem since the expectation upon which the Q function depends is parameterized by the policy parameters.
 In light of the smashing success of
In light of the smashing success of 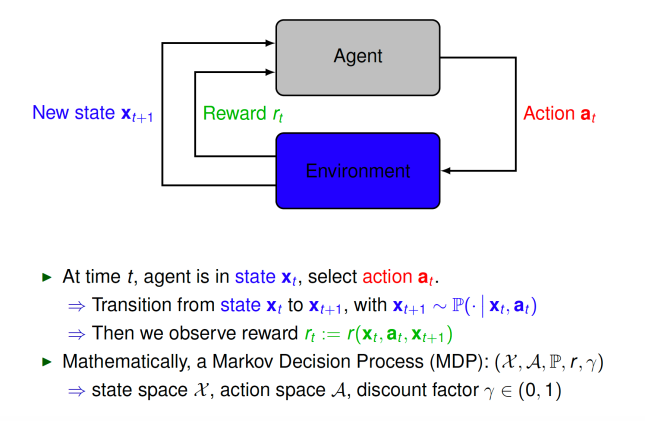 Here I am discussing the most general case where state and action spaces are continuous, which is in contrast to the context in which classical dynamic programming theory was developed. The average accumulation of rewards when starting in a given state is called its value:
Here I am discussing the most general case where state and action spaces are continuous, which is in contrast to the context in which classical dynamic programming theory was developed. The average accumulation of rewards when starting in a given state is called its value: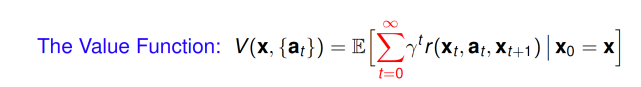 The goal in reinforcement learning is to chose the action sequence so as to accumulate the most rewards on average. Thus, our target is always to find the action sequence which gives us the most value:
The goal in reinforcement learning is to chose the action sequence so as to accumulate the most rewards on average. Thus, our target is always to find the action sequence which gives us the most value: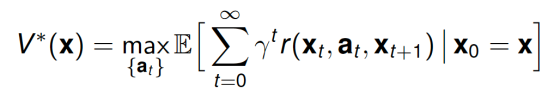 Now that we are all on the same page, we can talk about what are the difficulties of actually determining the optimal policy. I’ll organize the discussion according to the following table:
Now that we are all on the same page, we can talk about what are the difficulties of actually determining the optimal policy. I’ll organize the discussion according to the following table:

 The takeaway from this blog post is that (1) we would like to overcome non-convexity in policy learning. The only way to do this is with stochastic fixed point iteration, but we don’t know how to make this work with function approximation, which is required for continuous spaces; (2) non-convexity is a major contributor to the phenomenon called the explore-exploit tradeoff, for if we had convexity, through random exploration alone we would always eventually find the best policy; (3) on-policy policy learning can experimentally obtain very good results, but theoretically it requires treating trajectories through the space as time-series, a setting for which most understanding of statistical learning methods breaks down; and (4) hacks such as biasing action selection towards states that yield higher reward (greedy actions) can help us mitigate the explore-exploit tradeoff but we possibly do so at the cost of our learning process diverging.
The takeaway from this blog post is that (1) we would like to overcome non-convexity in policy learning. The only way to do this is with stochastic fixed point iteration, but we don’t know how to make this work with function approximation, which is required for continuous spaces; (2) non-convexity is a major contributor to the phenomenon called the explore-exploit tradeoff, for if we had convexity, through random exploration alone we would always eventually find the best policy; (3) on-policy policy learning can experimentally obtain very good results, but theoretically it requires treating trajectories through the space as time-series, a setting for which most understanding of statistical learning methods breaks down; and (4) hacks such as biasing action selection towards states that yield higher reward (greedy actions) can help us mitigate the explore-exploit tradeoff but we possibly do so at the cost of our learning process diverging.